meta data for this page
Chapter 6 Run Simulation
Version 1.5, © 2014 jeplus.org
6.1 EnergyPlus executables
The EnergyPlus installation settings include the directory for EnergyPlus binaries, command for EP-Macro, EnergyPlus and ReadVarsESO. If the default location (to your platform) of EnergyPlus and the commands are invalid, the text will be rendered RED. In such case, please use the browse buttons to locate the correct directory and commands. Once you have finished locating the commands, simply close this window. Your settings will be saved in a text file named “jeplus.cfg”, which will be loaded automatically the next time you run jEPlus. Please note that jEPlus does not support any pre-processing or post-processing utilities other than those listed on the GUI (Figure 9). If your model requires certain data set in EnergyPlus’s directory, it may not work with jEPlus. Should this be the case, please contact Yi for a solution.
6.2 Execution options
The Execution options tab controls the way the simulation jobs are executed. Firstly you can select how many processor cores to deploy for parallel simulation. jEPlus detects the number of processor cores in your computer automatically.
E+ version 7.1 and 7.2 included multi-threading support through OMP. Some building models may benefit from this feature. However, running multiple jobs in parallel will (always) be faster than running multi-threaded OMP jobs in sequence. jEPlus will set the E+ OMP parameter to 1. This can be overridden, however, if your IDF model contains an OMP block, in which case you should adjust the number of parallel jobs accordingly.
The working directory is where all individual job folders are stored. You will find the project result files (e.g. SimResults.csv) there, too. If relative path (see Path) is used, it is relative to the location of the current project file.
There are a number of options to reduce the number of files stored in individual job folders. You can specify which file(s) to delete after simulation. Syntax supports wildcard characters.
6.3 Run project
Three methods have been provided to test a small number of jobs before running the whole lot. This will help check model templates and parameter settings. The second option, ‘Randomly sample N jobs’, randomly shuffles all jobs first, and then run the first N jobs in the new list.
To start the batch run of the whole project, click on the ‘Start simulation’ button. Apart from the progress report on the ‘Output’ tab, you can also monitor the progress by checking the job directories generated in the work directory. If you have selected to keep all temporary file, it will be possible to diagnose problems with each job by examining the EnergyPlus reports. jEPlus will generate two log files during the execution. “jeplus.err” contains critical errors related to the program itself, whereas “jeplus.log” tracks output from EnergyPlus tools, therefore is useful for identifying problems with the model and jobs.
6.4 Latin Hypercube Sampling
Latin Hypercube Sampling (see LHS) is implemented in version 1.3. There are some limitations to the current implementation. Firstly, only the parameters in the first branch of the parameter tree are used in LHS. Secondly, if no probabilistic distribution function (PDF) is specified for a parameter, it is assumed to have a discrete distribution with each alternative value having the same probability. If a PDF is specified using @sample syntax, the number of samples param of the parameter will be overridden by the sample size param for the project.
Unlike the standard random sample methods, LHS does not require all jobs being created before taking a sample. It is therefore much faster and appropriate for large projects.
6.5 Simulation Control
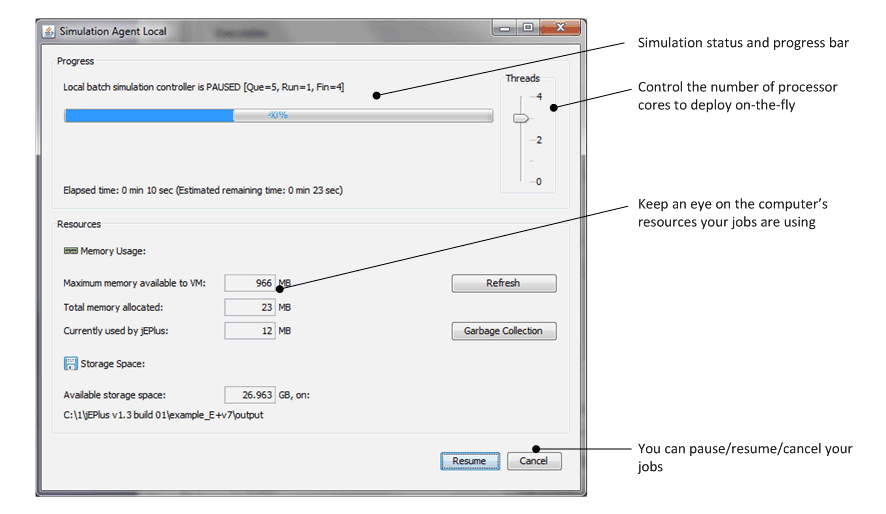
The simulation monitor (Figure 5.1) provides more control over the execution of the simulation jobs. Here you can dynamically adjust the number processor threads used for simulations, pause and resume the process, and keep an eye on the available resources.
6.6 Result and Report Tables
EnergyPlus simulations can generate large amount of output. Rarely all of these information are required for (especially) a parametric study. A good practice is to define as few output as possible in the EnergyPlus models, and to extract exactly the information required for further analysis. jEPlus will collect CSV tables from each job directory, and compile a single table containing all results from the batch. The summary data table is named SimResults.csv and is stored in the Work directory. Also stored are RunTimes.csv and SimJobIndex.csv, which contain EnergyPlus simulation error count and CPU time, and the corresponding index table of the jobs.
In version 1.5, most of the output file names can be defined by the user, especially when using the new RVX. If SQLite output is generate by the IDF model, and the sqls section is present in the RVX file, jEPlus will extract results from eplusout.sql files. Result tables will be named as specified by the user. If Python scripts are used, you should make sure that the scripts write the correct tables with the specified names. The “Action/View result” menu provides a convenient way to browse all result tables. At the end of result collection, jEPlus will generate two files named AllCombinedResults.csv and AllDerivedResults.csv, respectively, which aggregate the output tables.
A few addition commands are provided on the “Action” menu, to generate various job index files. The full Job Index file can be generated using the ‘Create Job List…’ command, which will list all jobs of the project in a CSV table. Parameter indexes can be generated by the “Generate Parameter Index” command. This will create a set of CSV files for individual parameters, and a SQL script that creates parameter index tables in a database.
6.7 Locating errors
jEPlus works as a simulation manager and a shell of the simulation engines, namely EnergyPlus, TRNSYS and INSEL. Any errors or information reported by the simulation engines are logged in the console.log files in the individual jobs folders. If your model does not generate the results you expect, these log files should tell you if your model is working correctly.
Errors or exceptions jEPlus itself encounters are logged in the jeplus.err file in the folder where jEPlus was started. Note that if you started jEPlus by double-clicking on the jEPlus.jar file on a Linux machine, the current folder may be the user's home, instead of where jEPlus.jar is located. There is a direct link to the this file in the Tools menu. Send us this file when you reporting an issue. It will help us locating the problems.