meta data for this page
Chapter 8 Using Python Script in jEPlus
Version 1.7, © 2016 jeplus.org
Since version 1.7, Python scripts can be used in both pre-processing of the models, and post-processing of the simulation results. This chapter is for explaining both processes.
In the pre-processing steps of jEPlus, user can use Python script to manipulate IDF models at will, especially by using Eppy, while taking account of predefined parameters in the project. Similarly in post-processing, Python can further extend the ability of gathering results and performing user defined analysis before jEPlus aggregates result tables. This is a very powerful feature and creates near infinite possibilities.
Set up Python environment
jEPlus has built-in Jython (Python language implemented in Java and runs on a Java virtual machine, equivalent to Python 2.7 with core libraries). It is convenient for people who do not need to full power of Python nor have C Python installed on their computers. It has a few limitations:
- Language level support: Python 2.7
- Only the core libraries, no extensions or plugins available
- Script will be executed in the jEPlus folder, instead of the project output folder or the individual job folder
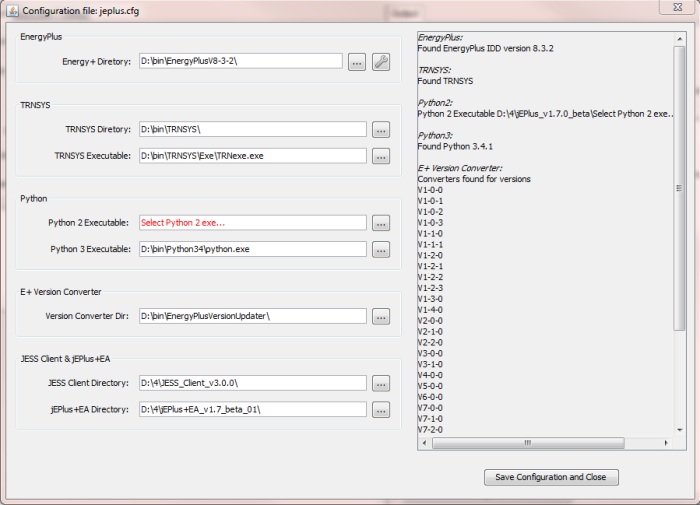
If you want to use additional libraries such as SciPy and Eppy, you will need to install CPython (v2 or v3) and let jEPlus know where they are. Configuring Python executable in jEPlus can be done using the “Configure External Programs…” dialog, shown in the screenshot below. It is accessible through Tools/Configure External Programs… menu.
Pre-processing
How does it work
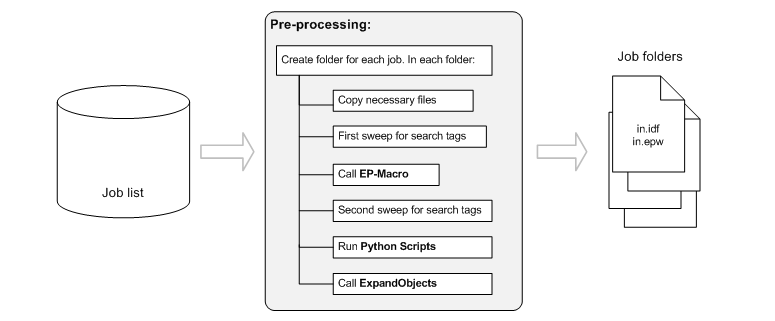
The diagram below is the pre-processing steps for preparing the EnergyPlus model for each case. The step of using an arbitrary Python script to manipulate the model is inserted right before the last step, calling ExpandObject. At this stage jEPlus has done all its processes, and the in.idf is ready in the case's folder. So the idea is that a users script can apply further operations on the in.idf file, using the arguments defined in the parameter and paths names passed in by jEPlus.
Calling convention
jEPlus calls the named script file in the project folder and passes in four arguments:
- Sys.argv[1] - project's base folder where the project files (e.g.
project.jep) are located - Sys.argv[2] - folder of the current case where
in.idf(orin.dckand so forth) is located - Sys.argv[3] - Other arguments specified in the parameter definition, as a ',' delimited string
- Sys.argv[4] - The location of the binary files of the simulation program, e.g. the location of Energy+.idd. This argument is only relevant with EnergyPlus simulations
It is expected that the script will take the existing in.idf, make changes, and produce a valid new in.idf that is ready for E+ simulation.
Parameter syntax
Here is an example of the parameter definition:
@python2(preproc_test_jy.py, P2, 99, P4, 222, abc)
It is led by the keyword @jython, @python2, or @python3 that specifies the flavour of the script file. In the brackets the first field is the name of the script file. Both relative and absolution paths names can be used here. If relative path is used, it is relative to the project's folder.
The following fields in the brackets are arguments to be passed to the script. Please note if jEPlus parameter names present in the project are used, the values of the parameters for each case will be taken. This allows the scripts to work with existing parameters.
In the given example, arguments 99, 222 and abc will be passed to the script as they are. P2 and P4, on the other hand, will be replaced by e.g. 1000 and 1.05 before being passed to the script.
If the syntax of the parameter is valid, you shall see it being displayed in a different format in the Preview box, as:
{call(python2, preproc_test_jy.py, @@cost1@@, 99, @@sizing@@, 222, abc)}
Example project for testing
example_3-RVX_v1.6_E+v8.3/ has been modified to demonstrate the Python functions. In the folder, a Python2 script for pre-processing, preproc_test_jy.py is included in the folder. The script does nothing except prints out the system arguments it receives upon being called by jEPlus.
The parameter holding the test Python script in the project is as below:
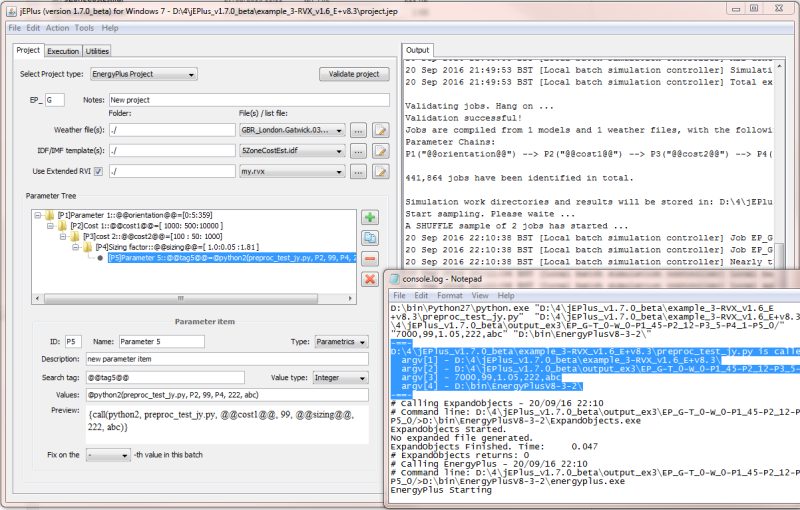
If the example worked correctly, arguments that have been passed to the Python script will be written to the logs, as shown in the screenshot above.
Example project for changing WWR
example_8-PyPreProcess_E+v8.5 contains the windown-to-wall ratio example. In the project, a jEPlus parameter defines the alt WWR values of all external walls. The Python script (written in Python3 and Eppy) takes the WWR value and applies it to all window objects in the IDF.

Please note, to run this example, you need to have Python3 and the Eppy dependencies installed.
Result collection and processing
Running Python scripts in the data collection process was introduced in version 1.6. This gives user virtually infinite possibilities for post-processing simulation results. Here is the scripts components in the RVX for specifying Python scripts for extracting data.
...
"scripts" : [
{
"fileName" : "calcMaxOfColumn_jy.py",
"pythonVersion" : "jython",
"onEachJob" : true,
"arguments" : "HourlyMeters",
"tableName" : "ElecPeakLoad"
},
{
"fileName" : "readRunTimes_jy.py",
"pythonVersion" : "jython",
"onEachJob" : false,
"arguments" : "",
"tableName" : "CpuTime"
}
],
...
Description of the fields
The fields in each script item require a bit of explaination:
fileName– The file name of the Python script. If full path is not provided, it is relative to the location of this RVX file.pythonVersion– Unfortunately the Python language differs between version 2 and 3. There are also restrictions depending on the interpreter used. In this field you can selectjython,python2orpython3.onEachJob–trueorfalse. If true, the script will be executed in each job folder, otherwise in the project's output folder where the individual job folders are located. If notonEachJob, a list of jobs in the project will be passed to the script as the second argument.arguments– You can provide additional arguments to be passed to the script. All additional arguments should be specified in one text string, separated by,.tableName– The file name for the output table. Value of this field will be passed to the Python script as the third argument. The script is then responsible for producing a csv table similar to the RVI result.
Arguments passed to the script
The number of arguments jEPlus passes to the script varies depending on the onEachJob option. If the onEachJob field is set to false, jEPlus will pass five arguments in total to the script. The arguments can be read within the script using sys.argv[]. Note that sys.argv[0] always returns the name of the script.
- sys.argv[1] – the full paths of the location of the project itself
- sys.argv[2] – the full path of the output folder of the project where the individual job folders are located
- sys.argv[3] – the list of the job IDs of the simulations that have been executed
- sys.argv[4] – the expected output table name, as defined by
tableName. jEPlus will add.csvto the table name before calling the script - sys.argv[5] – Other arguments as specified in the
scriptsobject in the RVX file
Otherwise, if the onEachJob option is true, the arguments passed are as below:
- sys.argv[1] – the full paths of the location of the project itself
- sys.argv[2] – the full path of the output folder of the simulation case
- sys.argv[3] – the expected output table name, as defined by
tableName. jEPlus will add.csvto the table name before calling the script - sys.argv[4] – Other arguments as specified in the
scriptsobject in the RVX file
Output table format
The Python scripts are responsible to produce suitable output tables that jEPlus can read and include into its result collection process. Depending on where the script is run, the output table formats are different.
If a script is run in the individual jobs folders, the output table should mimic the format of a typical eplusout.csv file generated by ReadVarsESO. Basically, the first column is date and time; the rest are data. Here is an example:
Date/Time,InteriorLights:Electricity [J](Hourly),InteriorEquipment:Electricity [J](Hourly),Heating:DistrictHeating [J](Hourly) 01/01 01:00:00,0.0,2276640.,13278931.1044949 01/01 02:00:00,0.0,2276640.,32229908.1477126 01/01 03:00:00,0.0,2276640.,17895859.9832406 01/01 04:00:00,0.0,2276640.,38784519.4821989 ...
A script running in the project's output folder should produce a table similar to SimResults.csv. The table should have three columns before the start of data. These three columns are the serial IDs, the job IDs, and a reserved column that can be anything or left empty. Below is an example. Please note the header row must start with #
#, Job_ID, Date/Time, Electricity:Facility [J](RunPeriod) 0, LHS-000000, simdays=62, 233879205202.003 1, LHS-000001, simdays=62, 236359323510.063 2, LHS-000002, simdays=62, 248514348464.105 3, LHS-000003, simdays=62, 232542002313.733 4, LHS-000004, simdays=62, 248299129214.135 5, LHS-000005, simdays=62, 250977825693.01 6, LHS-000006, simdays=62, 239737768305.779 ...
The example project
The following script is included in the example_3-RVX_v1.6_E+v8.3/ folder. It reads the RunTimes.csv table and calculates the CPU time in seconds, before writing the results to an output table. This script is just for demonstration purpose and has probably little practical use. However, you can see how scripts work with jEPlus.
# Example python script: This script reads from RunTimes.csv, calculates CPU time used in seconds,
# and then write to different table specified by the user.
# Arguments:
# sys.argv[1] - project's base folder where the project files are located
# sys.argv[2] - output folder of the project where the RunTimes.csv is located
# sys.argv[3] - the list of jobs have been executed in the project
# sys.argv[4] - user-defined output table name + .csv
# sys.argv[5..] - Other arguments specified in the RVX file
import sys
import _csv
import math
ifile = open(sys.argv[2] + "RunTimes.csv", "rt")
reader = _csv.reader(ifile)
ofile = open(sys.argv[2] + sys.argv[4], "wb")
writer = _csv.writer(ofile)
rownum = 0
timelist = []
for row in reader:
# Save header row.
if rownum == 0:
header = row[0:3]
header.append("CpuTime")
writer.writerow(header)
else:
time = [float(t) for t in row[5:]]
seconds = time[0]*3600+time[1]*60+time[2]
timelist.append(seconds)
temprow = row[0:3]
temprow.append(seconds)
writer.writerow(temprow)
rownum += 1
ifile.close()
ofile.close()
n = len(timelist)
mean = sum(timelist) / n
sd = math.sqrt(sum((x-mean)**2 for x in timelist) / n)
# Console output will be recorded in PyConsole.log
print '%(n)d jobs done, mean simulation time = %(mean).2fs, stdev = %(sd).2fs' % {'n':n, 'mean':mean, 'sd':sd}
The console errors and outputs (including the print… output) are logged in PyConsole.log file in the project's output folder. If a script is run in the individual job folders, the console logs are stored in the console.log files in each job folder.