meta data for this page
Chapter 6 Running Simulations
Version 2.1, © 2019, 2020 Energy Simulation Solutions Ltd
Running a parametric project may take a substantial amount of computing resources and time, hence you should always check and double-check your project before launching it. jEPlus provides functions to check the composition and details of the project and allows you to perform test runs in order to identify any potential problems. This chapter explains these tools and where to find the results tables and error logs.
6.1 Project validation
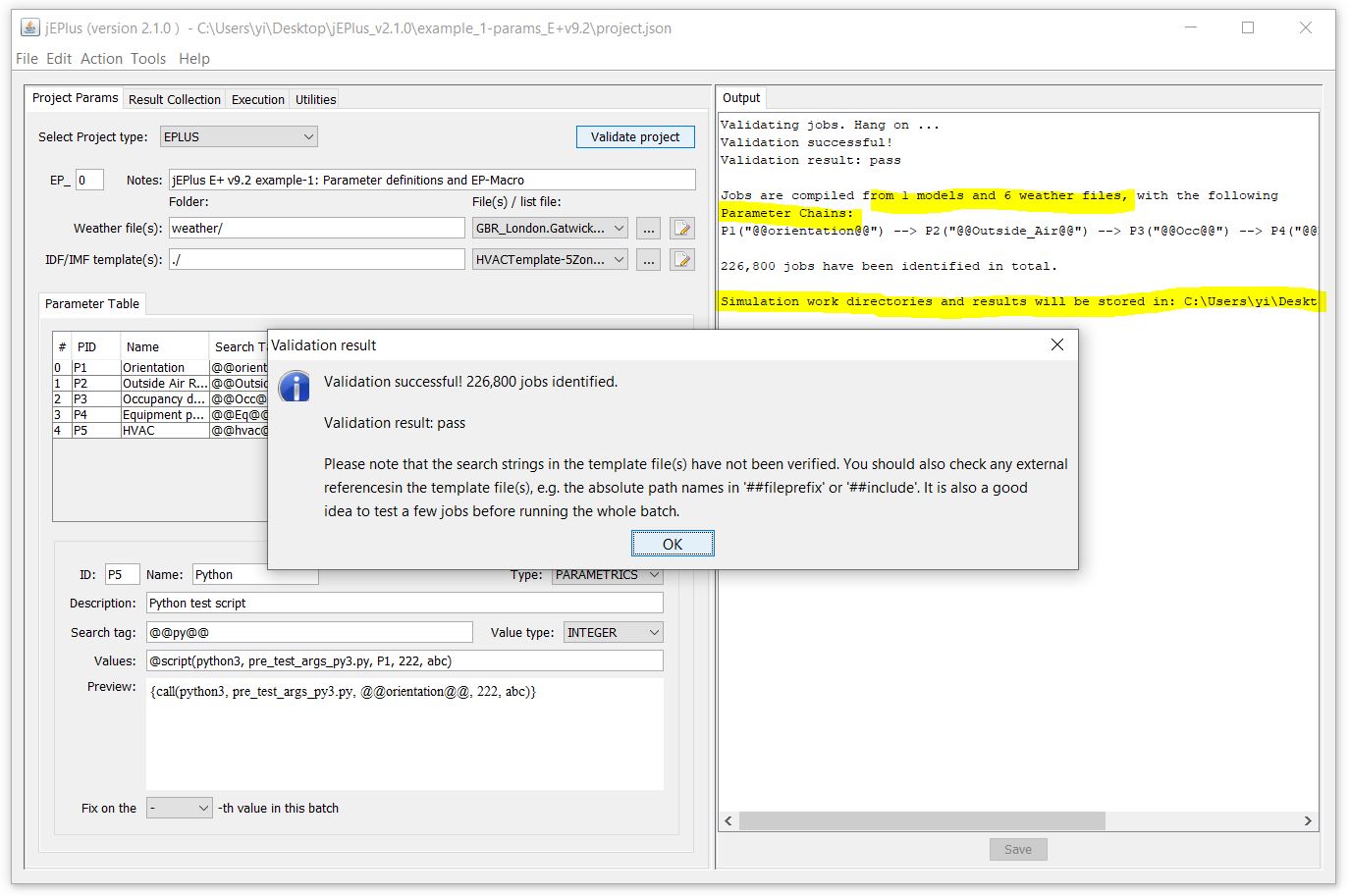
Once you have finished the preparation of the project, i.e. to define the input files, the parameters and the result collection methods, you can use the project validation function to check over the project composition by clicking on the Validate button on both the Project Params tab and the Execution tab. This function checks over the project in the following order:
- EnergyPlus or TRNSYS executables of the required version are accessible
- Working directory and input files are accessible
- Parameter names and search strings comply with relevant rules, e.g. no duplication
- Compilation of jobs is successful, hence validates the alternative value syntax of the parameters
- Checking if all referenced files, including those in the RVX object, are accessible
- Checking if any duplicates are present in the output tables to be generated by the RVX members
- Reporting number of jobs identified, including a list of parameter chains
If validation succeeds, a message box will appear to show the number of jobs found in the compiled job group. “Start simulation” button will be subsequently enabled. If there is an error, the message box will provide some diagnostic information to help you locate the issue.
Please note that the validation process DOES NOT verify the model templates, including the search strings, the EP-Macro ##include references. You should do a test run of the project and look into EnergyPlus or TRNSYS error logs to identify any problems.
6.2 Execution settings object
If project validation is successful, you are now ready to run. There are a bunch of execution settings and options that are described in this chapter. Take a look at the jEPlus project in the example folder, you will see that it contains an object called execSettings. This object stores the options you have set on the Execution tab of the GUI. Here are its contents:
{
...
"execSettings" : {
"numThreads" : 16,
"workDir" : "../output_ex2/",
"subSet" : 2,
"sampleOpt" : "SHUFFLE",
"randomSeed" : 12345,
"numberOfJobs" : 5,
"jobListFile" : "select job list file ...",
"rerunAll" : true,
"keepJEPlusFiles" : true,
"keepEPlusFiles" : true,
"deleteSelectedFiles" : false,
"selectedFiles" : "*.dxf *.htm *.mtd *.mdd *.rdd *.shd *.out *.audit *.eio *.idd *.bnd *.ini",
"timeout" : 0,
"steps" : {
"writeJobList" : true,
"jobListFile" : "joblist_out.csv",
"prepareJobs" : true,
"collectResults" : true,
"runSimulations" : true
}
}
}
These section of a project file is also useful when you want to run the project using the jEPlus CLI (see chapter 9). In this chapter, we will examine the GUI while explaining these execution settings.
6.3 Execution mode
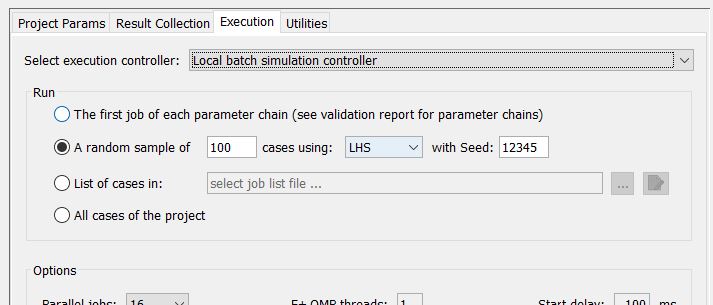
There are four modes to do test or full runs of a jEPlus project.
Parameter chains
The “parameter chain” test can be used to test all combinations of the input files, i.e. all combinations of the model templates and the weather files in the case of EnergyPlus, using the first set of parameter values only.
Random sampling
Run a ramdom sample of a project can be used for either testing the models with various parameter values, or performing uncertainty and sensitivity analysis. Three random sampling methods are supported in jEPlus. These are:
- Shuffling - jEPlus compiles all the cases of the project, shuffle the order of the list, and then run the first N cases in the now randomly ordered list. If the project is large, e.g. containing millions of cases, the shuffling process can take a very long time. A warning will be displayed to suggest the use of other sampling methods.
- Latin Hypercube Sampling (see LHS) - can typically produce a good sample representative of the whole parametric space using a sample size as low as 10 x number of parameters. If no probabilistic distribution function (PDF) is specified for a parameter, it is assumed to have a discrete distribution with each alternative value having the same probability. If a PDF is specified using
@samplesyntax, the number of samples param of the parameter will be overridden by the sample size param for the project. Unlike the standard random sample methods, LHS does not require all jobs being created before taking a sample. It is therefore much faster and appropriate for large projects.
- Sobol sequence (see SOBOL) - another method for producing homogenous samples across the parametric space, though generally requiring larger sample sizes than LHS.
Job list file
You can create a job list file to define a number of simulation cases for jEPlus to run. The format of a job list file is detailed in Chapter 9. This method is useful when you use an external program (e.g. SimLab) to perform sampling or have an arbitrary list of cases to run.
All
This will run all the cases in the project, taking into account of any parameters whose values are fixed with the selectedAltValue field.
6.4 Execution options
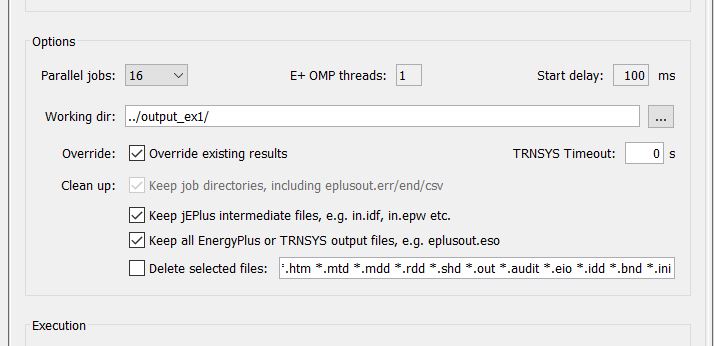
The Execution options section controls the way the simulation jobs are executed. Firstly you can select how many processor threads to deploy for parallel simulation. jEPlus detects the maximum number of processor threads in your computer and tries to use them all by default. If you want to continue using the computer when the simulations are running, reduce the number and free up a few processor cores.
The working directory (also referred to as the “output folder”) is where all individual job folders are stored. You will find the project result files (e.g. SimResults.csv) there, too. If a relative path (see Path) is used, it is relative to the location of the project file.
Two new options have been added in jEPlus v2.1. First, you need to be aware that jEPlus does NOT clear the output folder for each run. It overrides any existing results by default. However, if the Override existing results option is unchecked, jEPlus will skip any cases that it can see results files already exist in the output folder.
For TRNSYS simulations, if there is an error in the program, TRNSYS may show a dialogue window prompting for user confirmation. By setting the TRNSYS Timeout option to a possible number, the TRNSYS program will be forcefully terminated after this number of seconds to allow the parametric simulations to continue.
There are a number of options to reduce the number of files stored in individual job folders. You can specify which file(s) to delete after simulation. Syntax supports wildcard characters.
6.5 Execution steps
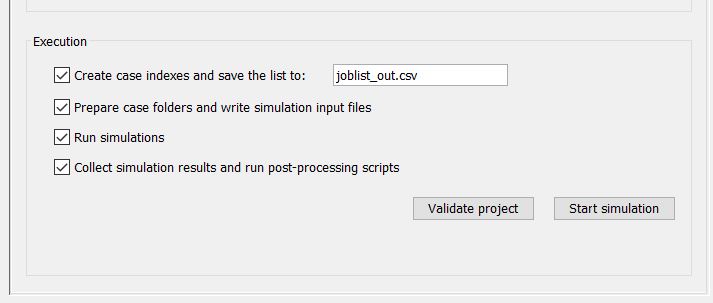
If you recall the process of jEPlus described in Chapter 1, there are four distinctive steps jEPlus takes to run a project. The user can control whether or not to perform any of the steps when the Start Simulation button is clicked.
Compiling cases

The figure to the right illustrates the default naming convention of the simulation cases (jobs) generated from the parameter tree. The first three nodes in the tree, i.e. the Group ID (identified by “G” + user-specified integer), the IDFs (“T”) and the Weather Files (“W”) are implicit and default to all projects. Here is an example job id: G_0-T_0-W_0-P1_19-P2_2-P3_1.
As you can imagine, even with short parameter names, the job id can grow quite long with an increasing number of parameters. This may subsequently cause issues with creating job folders on the file system. A rule is set in jEPlus so that if there are seven or more parameters in the project, the full job IDs will not be used. Instead, each simulation case will be given a serial number. The same is true if either the LHS or the SOBOL random sampling method is used.
jEPlus creates simulation cases by traversing the parameter tree. Each job is a path from the top of the tree to the bottom, with each node containing an optional value of the corresponding parameter. As a result, the total number of jobs defined by the tree equals the total number of the possible paths. jEPlus will compile these cases and write the list to a job list file to be executed.
Preparing simulations
In the preparation step, all the simulation job folders will be created in the output folder, which itself would have been created during validation. jEPlus then copies the case files to each of their folders, performs search and replace operations to insert parameter values, calls EP-Macro, then sweep for parameters again, before running any pre-processing scripts on the case model. Once the preparation is done, each job folder should contain a pair of the model (in.idf) and weather file (in.epw), along with some intermediate files and logs (console.log).
Running simulations
jEPlus then calls EnergyPlus or TRNSYS from each job folder to carry out the actual simulations. You will see the simulation output files being created in the job folders. The appearance of eplusout.end file in the folder marks the end of the simulation for each case.
Collecting results
Finally, jEPlus performs the result collection and post-processing tasks on the simulation outputs, and aggregate results into a pair of summary tables, namely AllCombinedResults.csv and AllDerivedResults.csv.
The ability to pick any individual steps to run gives the user more control over the execution of the project.
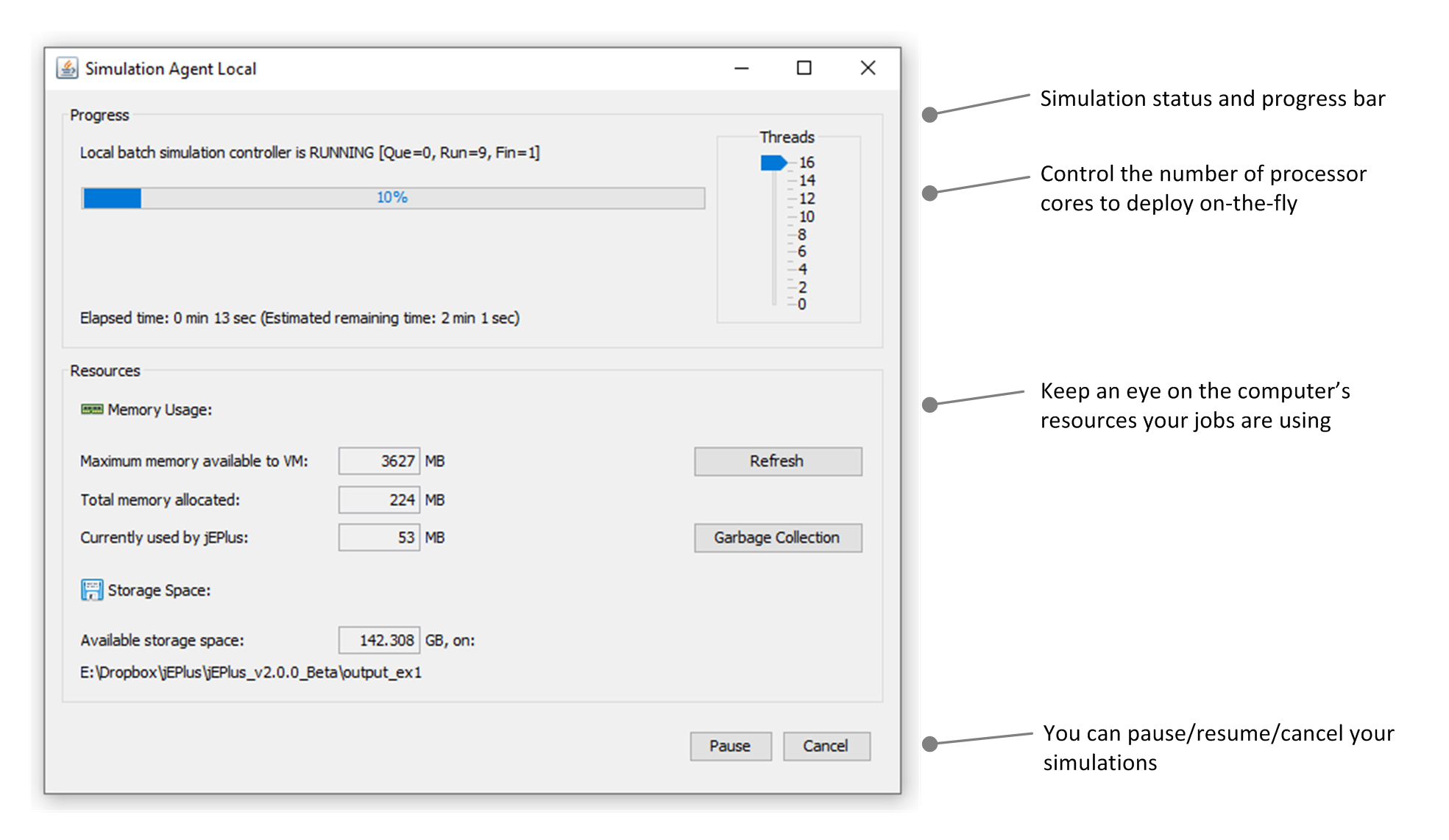
6.6 Simulation Control
The simulation monitor provides more control over the execution of the simulation jobs. Here you can dynamically adjust the number processor threads used for simulations, pause and resume the process, and keep an eye on the available resources.
6.7 Result and Report Tables
EnergyPlus simulations can generate a large amount of output data. Rarely all of these outputs are required for a parametric study. A good practice is to request as few outputs as possible in the EnergyPlus models and to extract exactly the information required for further analysis. This will save disk space, reduce jEPlus' memory footprint, and make the whole project run faster as well.
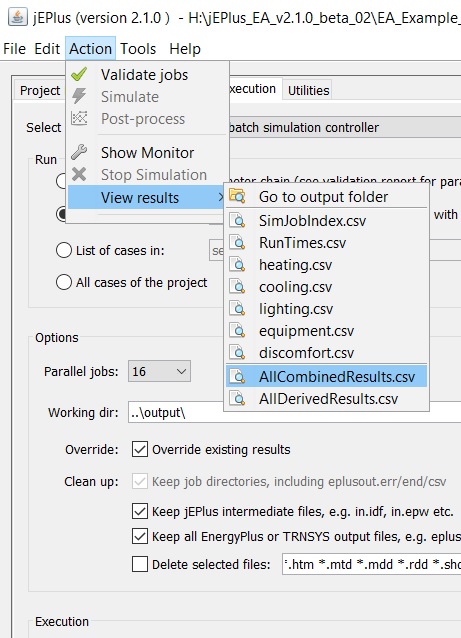
Once all the simulations have finished, jEPlus runs the results collection and post-processing tasks defined in the RVX object. You can see the CSV tables defined for each RVX element being created in both the job folders and copied to the output folder if aggregation is requested. In the end, two aggregated results files will be created. They are AllCombinedResults.csv and AllDerivedResults.csv, along with RunTimes.csv and SimJobIndex.csv containing the simulation outcomes and job indices, respectively.
You can find the output folder and all the generated results tables using the Action/View Resutls menu.
6.8 Simulation & error logs
If the summary table(s) come back empty, there are three places to look for log files that can help you figure out what the problem is. The first place to check if the jeplus.err file in the jEPlus program's folder, which contains the program's error logs. The second place to check is the console.log files in each job folder, which record the console output from the external programs such as EP-Macro, EnergyPlus, TRNSYS, and the script engines used in the project. There may also be a console.log present in the output folder, which includes the logs written by any scripts running at the project level. If an EnergyPlus or TRNSYS simulation has failed, you will see an entry in the RunTimes.csv table. Check the simulation job's own error log file, eplusout.err for EnergyPlus, to diagnose the issue.
More information on how to find errors and diagnose issues is available in the Q&A section of Chapter 10.