meta data for this page
Chapter 5 Result Extraction
Version 2.1, © 2019, 2020 Energy Simulation Solutions Ltd
Extracting and aggregating EnergyPlus results is one of jEPlus' key functions. It can get data out of EnergyPlus' time series outputs in ESO/MTR, or tabular reports in CSV. It can also run SQL queries on SQLite outputs. What's more, you can implement your own results extraction methods using scripts, and perform post-processing operations using scripts and simple formula. This chapter describes various methods available.
5.1 The RVX Object
“RVX” used to stand for the “RVI-extended” file that was introduced in jEPlus v1.5. In v2.x, of course, the means of collecting simulation results and performing post-processing operations have been substantially expanded. The name is kept and now it should probably mean “result value extraction” or whatever.
Here is the skeleton of the RVX object:
{
...
"rvx" : {
"rvis" : [ ],
"csvs" : [ ],
"sqls" : [ ],
"scripts" : [ ],
"userSupplied" : [ ],
"trns" : [ ],
"userVars" : [ ],
"objectives" : [ ],
"constraints" : [ ]
},
...
}
The rvis, csvs and sqls are EnergyPlus-specific, whereas the trns are for TRNSYS only. The other members are applicable to both EnergyPlus and TRNSYS projects. We are going through the details of each member of the RVX object in this chapter.
5.2 'rvis' - using ReadVarsEso
ReadVarsESO is a very useful tool in EnergyPlus and has been used in jEPlus since its first release. ReadVarsESO extract data of user-selected variables from the standard EnergyPlus output files (eplusout.eso and eplusout.mtr) and reformat it as a CSV file. More details of how ReadVarsESO works can be found in EnergyPlus' documentation. To use ReadVarsESO, you need to specify an RVI or MVI file, which contains the name of the EnergyPlus output file (either eplusout.eso or eplusout.mtr), the name of the output CSV file (must be eplusout.csv), a list of output variables to extract, and a 0 in the last row to mark the end of the file. The list below shows an example of RVI.
eplusout.mtr eplusout.csv Electricity:Facility 0
The available output variable names of your model are reported in eplusout.rdd and eplusout.mdd (or your_model_name.mdd/rdd, if you simulated the model with EP-Launch) files. Below is (part of) an example eplusout.mdd file, in which you can see where the variable names are specified. Please note the variables must be specified for output at the desired frequency in the IDF model, too. A more detailed explanation can be found in the answers to this question on UnmetHours.
Program Version,EnergyPlus-32 7.0.0.036, 06/06/2013 20:46,IDD_Version 7.0.0.036 Var Type (reported time step),Var Report Type,Variable Name [Units] Zone,Meter,Electricity:Facility [J] Zone,Meter,Electricity:Building [J] Zone,Meter,Electricity:Zone:SPACE1-1 [J] Zone,Meter,InteriorLights:Electricity [J] Zone,Meter,InteriorLights:Electricity:Zone:SPACE1-1 [J] Zone,Meter,GeneralLights:InteriorLights:Electricity [J] ...
In the RVX object, you can specify as many RVI files to use as you like in the rvis component. Below is an example showing the syntax. In addition to the RVI file name, you need to specify a tableName. During the result collection process, jEPlus uses each RVI to extract results to a eplusout.csv file, then renames it to [tableName].csv. You should make sure that a different table name is given to each RVI object.
The other two fields of the RVI object are quite important, too. The frequency field specifies the report frequency of the output variables to be extracted, and the usedInCalc field indicates whether the extracted table should be copied to the output folder and its columns included in the combined table after collection or not. When creating the combined tables, jEPlus simply takes the last row of all the data associated with the job ID, hence it does not make sense to set usedInCalc to true if frequency is anything but Annual or RunPeriod.
In the example below, the hourly results will be further processed using a Python script (see section 5.6), therefore they are intermediate data and should not be included in the final combined table.
...,
"rvis" : [
{
"fileName" : "AnnualCarbon.rvi",
"tableName" : "Carbon",
"frequency" : "Annual",
"usedInCalc" : true
},
{
"fileName" : "AnnualDiscomfort.rvi",
"tableName" : "Discomfort",
"frequency" : "Annual",
"usedInCalc" : true
},
{
"fileName" : "HourlyMeters.rvi",
"tableName" : "HourlyMeters",
"frequency" : "Hourly",
"usedInCalc" : false
}
],
...
5.3 'sqls' - E+ SQLite output
If you have instructed the EnergyPlus model to generate output in SQLite format, you may run SQL queries to extract desired results. You can use SQL objects to access both time series and tabular reports data. SQL is a powerful language and can be used to perform certain operations efficiently. However, since generating SQLite output bears significant computing cost, and extracting results can normally be done using either RVI or CSV (for tabular reports, see the next section) while post-processing with scripts, the SQL method is no longer recommended.
If SQL objects are specified, jEPlus will execute the SQL command using the built-in SQLite driver. For a tutorial on how to prepare SQLite instructions, please check out the video guide. The list below is the sqls component of the RVX object. Each SQL item has a tableName, a set of columnHeaders, and a sqlcommand. jEPlus will execute the sqlcommand on each job's eplusout.sql output file, and store result(s) in the [tableName].csv, with the given columnHeaders. You can have as many sql items in this section as you like.
...
"sqls" : [
{
"tableName" : "ChillerCap",
"columnHeaders" : "Chiller Nominal Capacity [W]",
"sqlcommand" : "select Value from ComponentSizes WHERE (CompType='Chiller:Electric' AND CompName='CHILLER PLANT CHILLER' AND Description='Design Size Nominal Capacity')",
"usedInCalc" : true
},
{
"tableName" : "ConsCost",
"columnHeaders" : "Construction Cost [$/m2]",
"sqlcommand" : "select Value from TabularDataWithStrings WHERE (ReportName='Construction Cost Estimate Summary' AND ReportForString='Entire Facility' AND TableName='Construction Cost Estimate Summary' AND RowName='Cost Per Conditioned Building Area (~~$~~/m2)' AND ColumnName='Reference Bldg.' AND Units='')",
"usedInCalc" : true
}
],
...
Two things require further attention when you are using sqls in the RVX. First is that the SQL command may need to be revised if you change E+ versions. Second, double quote (“) characters should be avoided if possible. If they must be used, escape the character with a backslash as \”.
5.4 'csvs' - E+ tabular report
The “CSV” method is the most convenient way to access summary outputs through EnergyPlus' tabular reports. It is much easier than SQL and much faster than RVI, hence deserves a priority consideration for extracting many common result values such as total consumption, design capacity and discomfort hours.
To enable CSV tabular report output from E+, you need to first add the highlighted object below in your model:
...
OutputControl:Table:Style,
CommaAndHTML; !- Column Separator
Output:Table:SummaryReports,
AllSummary; !- Report 1 Name
...
The resultant CSV tabular output (eplustbl.csv) is shown in the screenshot below. To locate a cell in the tables, you need to specify the report name, the table name, the column heading, and the row heading, as highlighted in the spreadsheet.
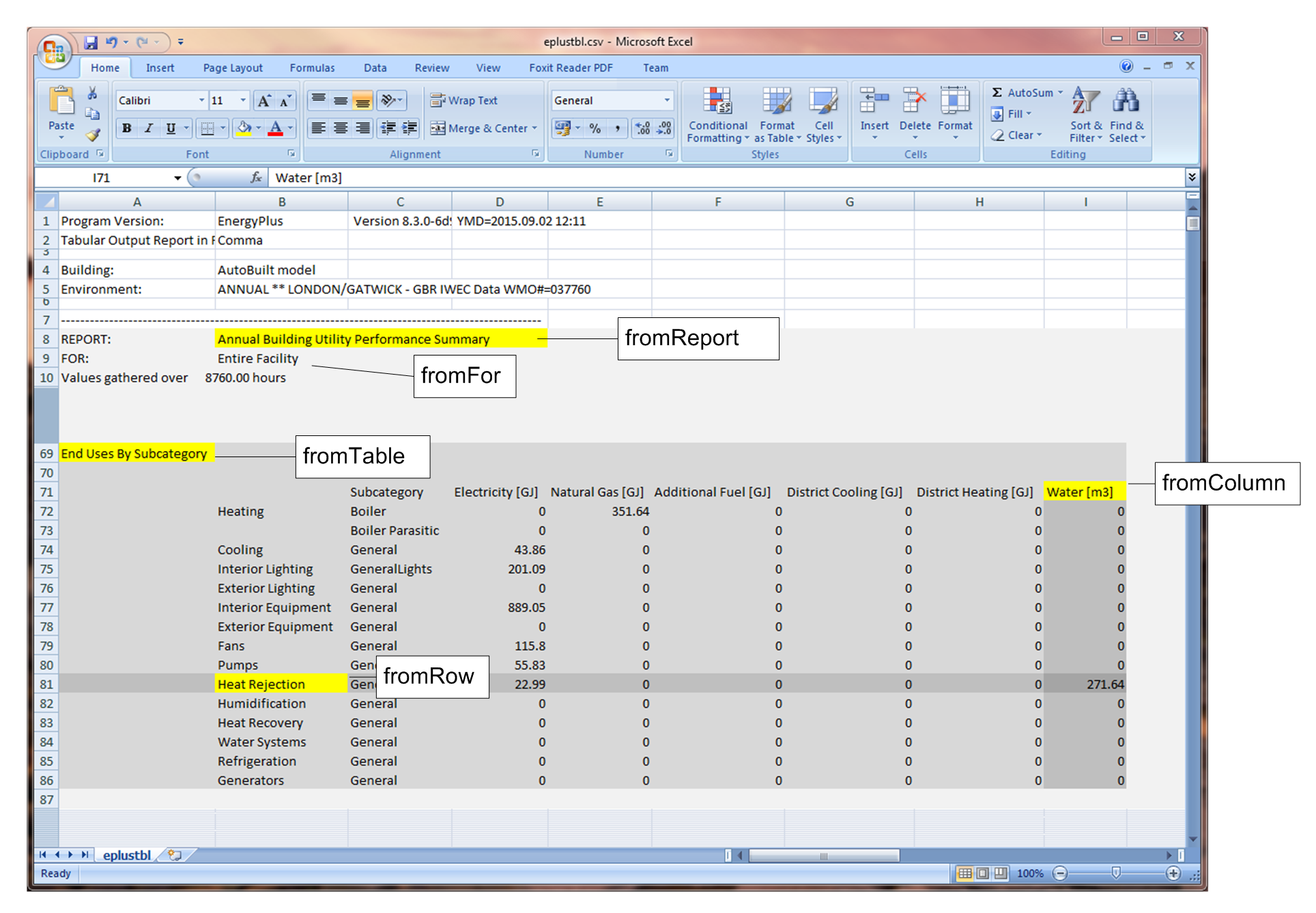
The CSVs objects in the RVX are fairly easy to understand. The specified the cell in eplustbl.csv will be collected and written to [tableName].csv, under the given new column header.
...
"csvs" : [
{
"sourceCsv" : "eplustbl.csv",
"fromReport" : "Annual Building Utility Performance Summary",
"fromFor" : "Entire Facility",
"fromTable" : "End Uses By Subcategory",
"fromColumn" : "Water [m3]",
"fromRow" : "Heat Rejection",
"tableName" : "WaterUse",
"columnHeaders" : "Water use for Heat Rejection [m3]",
"usedInCalc" : true
},
{
"sourceCsv" : "eplustbl.csv",
"fromReport" : "",
"fromFor" : "Entire Facility",
"fromTable" : "Heating Coils",
"fromColumn" : "Nominal Total Capacity [W]",
"fromRow" : "TEST AIR-TO-AIR HEAT PUMP HP HEATING COIL",
"tableName" : "CoilCapacity",
"columnHeaders" : "Nominal Total Capacity - HP Heating Coil [W]",
"usedInCalc" : true
}
],
...
5.5 'trns' - TRNSYS printers
Support for TRNSYS in jEPlus is still relatively simple. Result collection only support TRNSYS printer (Type 25) outputs in the forms of comma (,), space ( ) or tab (\t) delimited tables. What's more, jEPlus only collects the last row of the table, i.e. the aggregation field has only the LastRow option. Here is an example of the TRN object.
...
"trns" : [ {
"plotterName" : "plotter1",
"aggregation" : "LastRow",
"tableName" : "SimResults_plotter1",
"usedInCalc" : true
} ],
...
5.6 'scripts' - post-processing
Arguably the most significant new feature introduced since jEPlus v1.0 is the ability to run Python scripts in the result collection process. This gives the user the ability to extend jEPlus' functions with their own scripts, hence brought about virtually infinite possibilities for processing the simulation results to suit their needs.
In v2.1, jEPlus has further expanded support for different scripting languages. You will find an example project included in the distribution package to demonstrate how Python, R, Ruby and PHP scripts are called. A snippet is shown here.
...
"scripts" : [ {
"fileName" : "post_test_each_py3.py",
"onEachJob" : true,
"arguments" : "some;args",
"tableName" : "script_table1",
"language" : "python3"
}, {
"fileName" : "post_test_args.rb",
"onEachJob" : false,
"arguments" : "some;args",
"tableName" : "script_table4",
"language" : "ruby"
}],
...
Description of the fields
The fields of a script item require a bit of explanation:
fileName– The file name of the Python script. If the full path is not provided, it is relative to the location of this RVX file.onEachJob–trueorfalse. If true, the script will be executed in each job folder, otherwise in the project's output folder where the individual job folders are located. If notonEachJob, a list of jobs in the project will be passed to the script as the second argument.arguments– You can provide additional arguments to be passed to the script. All additional arguments should be specified in one text string, separated by,.tableName– The file name for the output table. Value of this field will be passed to the script as the third argument. The script is then responsible for producing a CSV table similar to the RVI result.language– The language can only be one that have been set up in the configuration dialogue (see Chapter 8). Please note that the language name matching is case-sensitive,Python2may give an error if the configured language ispython2.
Arguments passed to the script
The number of arguments jEPlus passes to the script varies depending on the onEachJob option. If the onEachJob field is set to false, jEPlus will pass five arguments in total to the script. The arguments can be read within the script using sys.argv[]. Note that sys.argv[0] always returns the name of the script.
- sys.argv[1] – the full paths of the location of the project itself
- sys.argv[2] – the full path of the output folder of the project where the individual job folders are located
- sys.argv[3] – the list of the job IDs of the simulations that have been executed
- sys.argv[4] – the expected output table name, as defined by
tableName. In the script,.csvshould be appended to the table name before written to the file - sys.argv[5] – Other arguments as specified in the
scriptsobject in the RVX file
Otherwise, if the onEachJob option is true, the arguments passed are as below:
- sys.argv[1] – the full paths of the location of the project itself
- sys.argv[2] – the full path of the output folder of the simulation case
- sys.argv[3] – the expected output table name, as defined by
tableName. In the script,.csvshould be appended to the table name before written to the file - sys.argv[4] – Other arguments as specified in the
scriptsobject in the RVX file
Output table format
The Python scripts are responsible to produce suitable output tables that jEPlus can read and include into its result collection process. Depending on where the script is run, the output table formats are different.
If a script is run in the individual jobs folders, the output table should mimic the format of a typical eplusout.csv file generated by ReadVarsESO. Basically, the first column is date and time; the rest are data. Here is an example:
Date/Time,InteriorLights:Electricity [J](Hourly),InteriorEquipment:Electricity [J](Hourly),Heating:DistrictHeating [J](Hourly) 01/01 01:00:00,0.0,2276640.,13278931.1044949 01/01 02:00:00,0.0,2276640.,32229908.1477126 01/01 03:00:00,0.0,2276640.,17895859.9832406 01/01 04:00:00,0.0,2276640.,38784519.4821989 ...
A script running in the project's output folder should produce a table similar to SimResults.csv. The table should have three columns before the start of data. These three columns are the serial IDs, the job IDs, and a reserved column that can be anything or left empty. Below is an example. Please note the header row must start with #
#, Job_ID, Date/Time, Electricity:Facility [J](RunPeriod) 0, LHS-000000, simdays=62, 233879205202.003 1, LHS-000001, simdays=62, 236359323510.063 2, LHS-000002, simdays=62, 248514348464.105 3, LHS-000003, simdays=62, 232542002313.733 4, LHS-000004, simdays=62, 248299129214.135 5, LHS-000005, simdays=62, 250977825693.01 6, LHS-000006, simdays=62, 239737768305.779 ...
An example
The following script is included in the example_3-RVX_v1.6_E+v8.3/ folder. It reads the RunTimes.csv table and calculates the CPU time in seconds, before writing the results to an output table. This script is just for demonstration purpose and has probably little practical use. However, you can see how scripts work with jEPlus.
# Example python script: This script reads from RunTimes.csv, calculates CPU time used in seconds,
# and then write to the different table specified by the user.
# Arguments:
# sys.argv[1] - project's base folder where the project files are located
# sys.argv[2] - output folder of the project where the RunTimes.csv is located
# sys.argv[3] - the list of jobs have been executed in the project
# sys.argv[4] - user-defined output table name + .csv
# sys.argv[5..] - Other arguments specified in the RVX file
import sys
import csv
import math
ifile = open(sys.argv[2] + "RunTimes.csv", "rt")
reader = _csv.reader(ifile)
ofile = open(sys.argv[2] + sys.argv[4], "wb")
writer = _csv.writer(ofile)
rownum = 0
timelist = []
for row in reader:
# Save header row.
if rownum == 0:
header = row[0:3]
header.append("CpuTime")
writer.writerow(header)
else:
time = [float(t) for t in row[5:]]
seconds = time[0]*3600+time[1]*60+time[2]
timelist.append(seconds)
temprow = row[0:3]
temprow.append(seconds)
writer.writerow(temprow)
rownum += 1
ifile.close()
ofile.close()
n = len(timelist)
mean = sum(timelist) / n
sd = math.sqrt(sum((x-mean)**2 for x in timelist) / n)
# Console output will be recorded in PyConsole.log
print '%(n)d jobs done, mean simulation time = %(mean).2fs, stdev = %(sd).2fs' % {'n':n, 'mean':mean, 'sd':sd}
Console logs
The console errors and outputs (including the print(…) outputs) are logged in two places. If the script is onEachJob, the log entries (marked by an opening and a closing === line) will be appended to the console.log file in each job folder. If it is global, i.e. executed after result extraction on each job is done, the script's log entries will be in the console.log file in the project's output folder. Using the log files can help you diagnose issues.
jEPlus also provides a script runner utility to help you test your scripts “offline”. See Chapter 7 for more details.
5.7 'userSupplied' - Additional Data
[to be updated]
There are situations where you may need extra data to be included in the results, e.g. to be considered in the optimisation process, that are not otherwise possible to generate by the simulation model. You may also want to tag certain combinations of model parameter values using another report variable. These can be achieved by using the userSupplied object to load the extra data from an external spreadsheet (in CSV format).
...
"userSupplied" : [
{
"fileName" : "feasible.csv",
"headerRow" : 0,
"jobIdColumn" : 0,
"dataColumns" : "1",
"missingValue" : 0,
"tableName" : "Filter"
}
],
...
This object specifies that the extra data are read from the file named feasible.csv. The file is expected to be located in the same folder as the project (.jep) file, as no paths information is given. The file, which must be in CSV format, contains the first row for the column headers, and the first column for the patterns for matching Job ID strings. The data column is in the second column. Please note that the quote marks around the value for dataColumns are necessary, as a string field is expected. If you have more than one data columns, list them with a space separated string, such as “1 3 4”. If jEPlus cannot find any entry in the spreadsheet corresponding to a job, it will use the missingValue, which defaults to 0. The extra data will be collected to a table named Filter.csv in this case.
Here is an example of the user supplied spreadsheet:
Job_ID,Disallowed
G-0_1_0_2_1_1,1
G-0_1_0_1_2_0,1
G-.+_1_.+_.+_.+_.+,1
G-.+_2_.+_.+_.+_.+,1
G-.+_3_.+_.+_.+_.+,1
...
The Job_ID column list the patterns using regular expression (Regex). There are rich resources available online for this powerful mechanism. You can develop and test your Regex here: https://regex101.com/, for example. For each simulation case, jEPlus tries to match its job ID in the list, and returns the first match it has found. So in this case, the order of the list may be significant.
5.8 'userVars' - report variables
Finally, we come to the derivative variables and metrics for further calculations and reporting. These are the userVars, constraints and objectives objects.
jEPlus allows users to define custom report variables calculated from the collected results and normalized metrics that can be used as penalty and fitness functions for optimisation. jEPlus will compute all these report variables and metrics after collecting simulation results, and put the values in the AllDerivedResults.csv file.
User-defined report variables (the userVars objects) has two purposes. First, it can be used to define what the jEPlus produce after running the simulations. This information is useful for importing the jEPlus project into jEPlus+EA, which is covered in the jEPlus+EA v2.x documentation. Second, the report variables may serve as intermediate variables in downstream calculations. This arrangement helps to break down long formulae and make them more manageable. There are four fields to specify a user variable. These are:
identifier- The identifier (variable name) of each variable must be uniqueformula- The expression for calculating the value of this variable. All collected simulation output values (c0,c1…) and variables defined before the current one can be used in the expression. Please note that the model parameters (e.g P1, P2…) are NOT available for calculations.caption- More description of the variable. This will be used as the column header for this variable in the report table.report- You can choose to include a variable in the output table or not.
...,
"userVars" : [ {
"identifier" : "v1",
"caption" : "Total electricity [kWh]",
"formula" : "c3/1000/3600+c8*1000/3.6/2.8",
"report" : true
}, {
"identifier" : "v2",
"caption" : "Total gas [kWh]",
"formula" : "c4/1000/3600+c7*1000/3.6/0.8",
"report" : true
} ],
...
5.9 'constraints' - penalty function
The constraints objects in the RVX is essentially any penalty function. It defines a “feasible” range between the lower bound (lb) and the upper bound (ub) values, and the “saturation” ranges if the value falls outside of the minimum (min) and the maximum (max) limits. If the constraint function value falls within the feasible range, the resultant penalty will be 0. If the constraint value falls in the saturation ranges, the penalty will be 1 (100%). Anything between min and lb, or between ub and max, are scaled linearly the yield a penalty value between 0% and 100%.
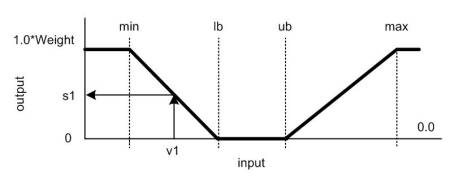
An example constraint definition is given below.
...,
"constraints" : [ {
"identifier" : "s1",
"caption" : "Lighting consumption [kWh]",
"formula" : "v3",
"scaling" : true,
"lb" : 0.0,
"ub" : 150.0,
"min" : 0.0,
"max" : 500.0,
"weight" : 1.0,
"enabled" : true
}, {
"identifier" : "s2",
"caption" : "Discomfort [Hrs]",
"formula" : "v4",
"scaling" : true,
"lb" : 0.0,
"ub" : 80.0,
"min" : 0.0,
"max" : 1500.0,
"weight" : 1.0,
"enabled" : true
} ],
...
5.10 'objectives' - fitness function
The “objectives” are a special concept in optimisation, which are used for guiding the exploration of solutions. Its formula is sometimes called a fitness function, literally, for measuring how “fit” is the solution to your problem. If you have moved from the previous versions of jEPlus to v2, please be aware that although the built-in scaling function has been kept for compatibility, it is not recommended and cannot be set through the GUI, as scaling is generally irrelevant to multi-objective optimisation algorithms. It may still be useful if you are doing single-objective optimisation by weighing and summing up different performance metrics. In this case, you can easily write the scaling function in the formula field.
...
"objectives" : [ {
"identifier" : "t1",
"caption" : "Total heating [kWh]",
"formula" : "v1",
"scaling" : false,
"min" : 0.0,
"max" : 1.0,
"weight" : 1.0,
"enabled" : true
}, {
"identifier" : "t2",
"caption" : "Total cooling [kWh]",
"formula" : "v2",
"scaling" : false,
"min" : 0.0,
"max" : 1.0,
"weight" : 1.0,
"enabled" : true
} ],
...