meta data for this page
Model calibration example
Back to Table of Contents
This page demonstrate an example application of jEPlus+EA for model calibration. The example is based on mocked data, in which the “measurements” are in fact simulation output of a special case of the same model. Obviously model calibration involves many practical yet challenging issues that have not been considered here. This simple example is only for the purpose of demonstrating the ability and the process of jEPlus+EA searching for parameter values that match the “measurement” data.
Building model and output data
The building models used in this example are the UK office building archetypal models that are available to download from the example projects section on this website.
The building models

There are four based building models, representing different geometries and internal layouts of small to median sized office buildings. Design parameters included in the models are orientation, glazing ratio, glazing coating options, overhang options, daylight controls, HVAC systems, and building fabrics. The choice of parameters is atypical to calibration applications, as the values of these parameters are normally easy to determine. However, from the optimisation algorithm's point of view, these parameters are discrete and potentially make the problem harder to solve.
Hourly meter data and RVI
The models are configured to report hourly meter data on electricity, (district) heating and cooling consumption, as shown in the IDF segment below.
!- =========== ALL OBJECTS IN CLASS: OUTPUT:METER =========== Output:Meter,InteriorLights:Electricity,Hourly; Output:Meter,InteriorEquipment:Electricity,Hourly; Output:Meter,Heating:DistrictHeating,Hourly; Output:Meter,Cooling:DistrictCooling,Hourly; Output:Meter,Fans:Electricity,Hourly; Output:Meter,Pumps:Electricity,Hourly;
The corresponding RVI file for extracting simulation output to a csv table using E+'s ReadVarsESO tool is as below:
eplusout.eso eplusout.csv InteriorLights:Electricity InteriorEquipment:Electricity Heating:DistrictHeating Cooling:DistrictCooling Fans:Electricity Pumps:Electricity 0
After running simulation and calling ReadVars, the CSV table of the hourly meter reading is like this:

The "measurement" data
The “measurement” data is in fact the model output of a selected simulation case. In this way, we dodged many real life complications such as data quality. It also makes it clear what is the solution we are looking, i.e. the case that has been used for generating the “measurement” data. The selected case is building model #2, orientation 0, glazing ratio 0.25, non-reflective coating, no overhang, no daylight control, radiant heating/cooling with aluminium panels, no insulation in the building fabrics and single glazing.
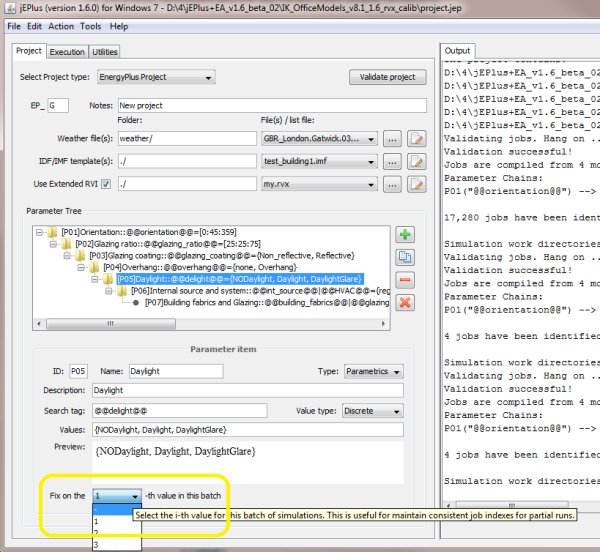
In jEPlus you can select and run a particular case in the whole project by fixing on the parameter values, as shown in the screenshot below. Alternatively, you can specify the case in a job list file to execute.
Evaluating simulation errors
Each simulation run will generate a set of hourly meter data from the model. These will be collected with ReadVars into a CSV table. We now need a utility to read this table and compare it with the reference data generated using the selected case. Writing a Python script would be a nice and easy way to do this.
The Python script
import pandas as pd
import numpy as np
import csv
import sys
# This file should be run within each job folder
# Arguments:
# sys.argv[1] - project's base folder where the project files, including
# the reference data file, are located
# sys.argv[2] - output folder of the project where job folders are located
# sys.argv[3] - user-defined output table name + .csv
# sys.argv[4] - Other arguments specified in the RVX file, in this case,
# the input table file name without extension, followed by
# the reference data file name. ("HourlyMeters;ref_jess.csv")
# function which calculates the root mean square error
def rmse_function(observed, predicted, N):
error = observed - predicted
sqerror = error ** 2
sumsqerror = np.sum(sqerror)
meansqerror = sumsqerror / N
rmse = np.sqrt(meansqerror)
return rmse
# This script takes
args = sys.argv[4].split(';')
# Read data from the reference file (paths and file name passed in through arguments)
refdata = pd.read_csv(sys.argv[1] + args[1])
in_file = sys.argv[2] + args[0] + ".csv"
indata = pd.read_csv(in_file)
rowcolno = indata.shape
heading = list(refdata.ix[:1]) #take heading row from the reference file
outname = sys.argv[3] # output file name from the parameter passed to the script
rmsedata = ["AAA"]
for column in range(1, rowcolno[1]):
observed = np.array(refdata.iloc[:, column])
predicted = np.array(indata.iloc[:, column])
rmse = rmse_function(observed, predicted, rowcolno[0])
rmsedata.append(rmse)
rmsedata = rmsedata
with open(outname, "w", newline='') as outfile:
output=csv.writer(outfile)
output.writerow(heading)
output.writerow(rmsedata)
Testing Python script
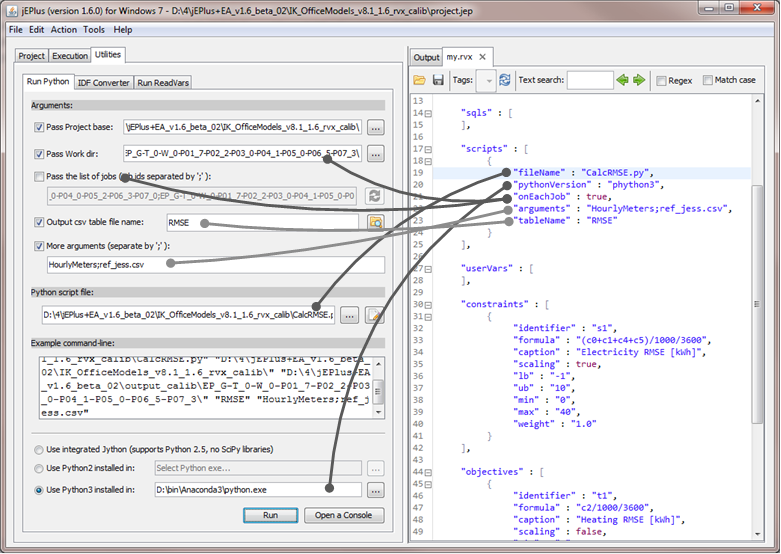
jEPlus provides a facility for testing Python scripts to be used in result collection and post-processing. In this example, we want to compare result from each simulation case to the reference, so we can make the Python script to run in each job folder. In the script object in RVX, the onEachJob field is set to true. This corresponds to disabling the third argument in the Python runner utility, and set the work dir argument to the job folder itself, as shown in the screenshot below.
The other fields of the script object have their suitable places on the utility's panel, too. Clicking on the Run button will execute the script. Any error messages will be shown in the Output tab.
The RVX
We have got nearly everything needed to set up the optimisation run. The only things that are missing are the objective functions. In this example, we use two objectives for minimizing heating and cooling prediction errors, and one constraint for the electricity prediction errors. There are other ways of assigning the objectives and constraints, such as using the CVRMSE and NMBE measures recommended in ASHRAE Guideline 14-2002. The selection of objective and constraints are actually quite important for solving the problem. We are not going into this topic right now.
The full RVX is shown below.
{
"notes" : "Some notes about this RVX",
"rvis" : [
{
"fileName" : "HourlyMeters.rvi",
"tableName" : "HourlyMeters",
"frequency" : "Hourly",
"usedInCalc" : false
}
],
"sqls" : [
],
"scripts" : [
{
"fileName" : "CalcRMSE.py",
"pythonVersion" : "phython3",
"onEachJob" : true,
"arguments" : "HourlyMeters;ref_jess.csv",
"tableName" : "RMSE"
}
],
"userVars" : [
],
"constraints" : [
{
"identifier" : "s1",
"formula" : "(c0+c1+c4+c5)/1000/3600",
"caption" : "Electricity RMSE [kWh]",
"scaling" : true,
"lb" : "-1",
"ub" : "10",
"min" : "0",
"max" : "40",
"weight" : "1.0"
}
],
"objectives" : [
{
"identifier" : "t1",
"formula" : "c2/1000/3600",
"caption" : "Heating RMSE [kWh]",
"scaling" : false,
"min" : "0",
"max" : "100000",
"weight" : "1.0"
},
{
"identifier" : "t2",
"formula" : "c3/1000/3600",
"caption" : "Cooling RMSE [kWh]",
"scaling" : false,
"min" : "0",
"max" : "1000",
"weight" : "1.0"
}
]
}
Running sample cases
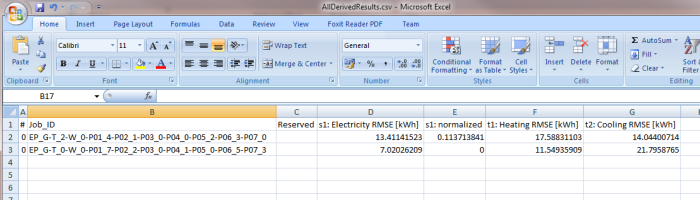
Now we are all set! But before running the optimisation, let's do a final test and see if everything works as they should. In jEPlus with the project is loaded, go the execution tab and run a random sample of four jobs. If all is well, we should get the AllDerivedResults.csv looking like this:
Setting up and running jEPlus+EA
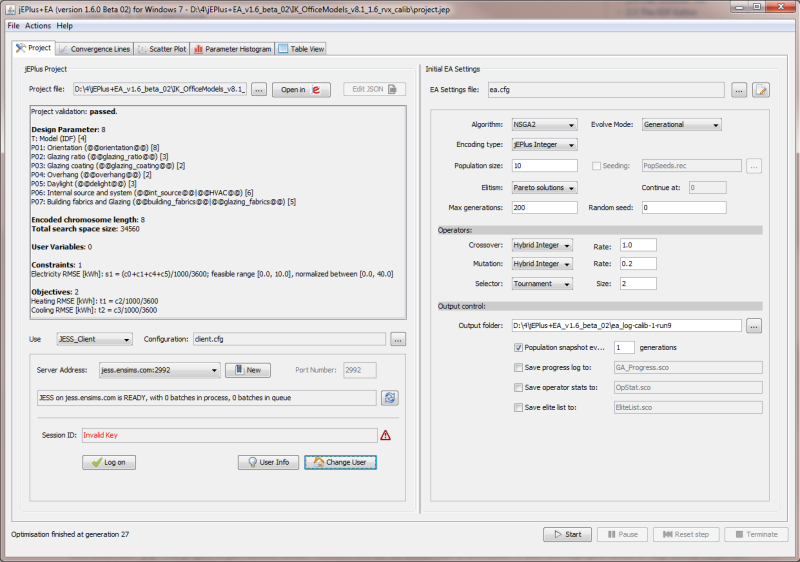
Setting up jEPlus+EA to run this calibration example is now a simple matter of loading the project. We don't even need to change the default EA settings. The screenshot above shows the project is loaded. The progress of EA is recorded in the screencast. Please note that, due to the stochastic nature of EA, it may take longer or short to find the reference case if this experiment is repeated.
Alternatively, you can download this video recording here: calibration-run.mp4
Resources
The project files of this example can be downloaded here: ik_officemodels_v8.1_1.6_rvx_calib.zip. Please note that this project works only with local simulations with Python 3 installed. To run it on the JESS server, you will need an enhanced account to enable Python functions.