meta data for this page
Run Optimisation in jEPlus+EA GUI
Back to Table of Content
Open jEPlus project
To start the GUI, double click on “run-jEPlus+EA.bat” (Windows) or “jEPlus+EA.jar”. Linux and Mac users may need to issue the following command from a terminal window:
java -jar jEPlus+EA.jar
The GUI is shown in the screenshot below. Click on the browse button next to the project file name box to select your optimisation project. You can start an instance of jEPlus within the GUI, to edit and test the project.
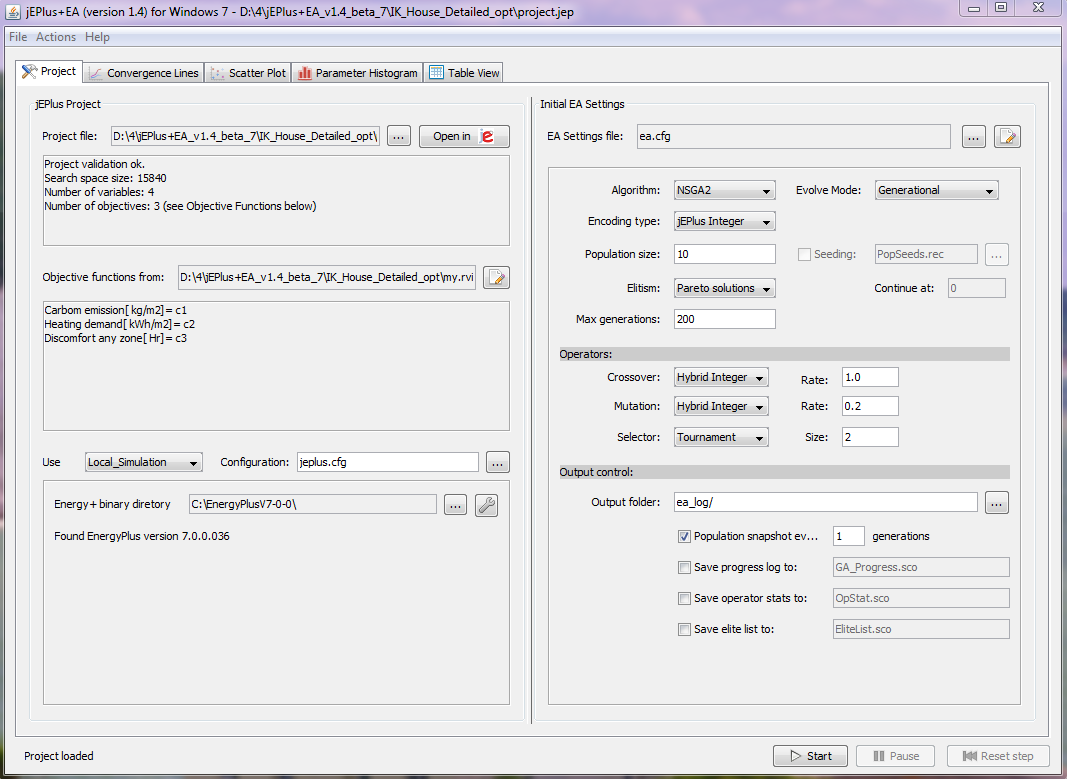
Information of the selected project is displayed. You can check the validation info, the search space size, the number of variables and objectives. Details of the objective definitions are shown in the next box. You can edit the RVI file by clicking on the edit button next to the file name. An warning message will be displayed if your computer does not have an associated editor for the RVI file.
Select simulation options
There are three options to run simulations for the optimisation purpose. Model simulations can be executed on the local computer (using jEPlus), a remote computer or cluster (using the JESS Client), or read from a pre-simulated result table. The last option is for developing the algorithm.
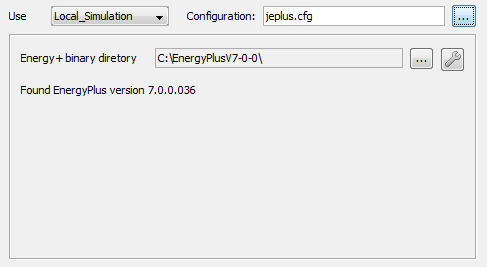
Local simulation
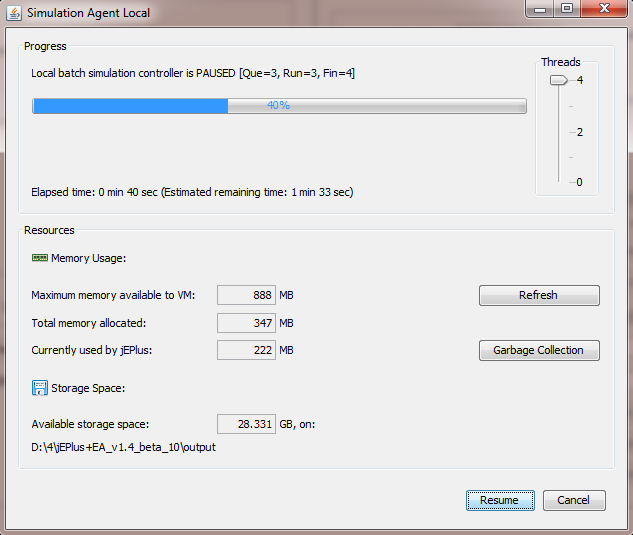
If local simulation option is selected. The box below will show the E+ executable to be used. You must select the correct E+ version to match your models. During the optimisation, the number of processor cores used can be adjusted using the control dialogue. Screenshots are shown below.
Remote simulation
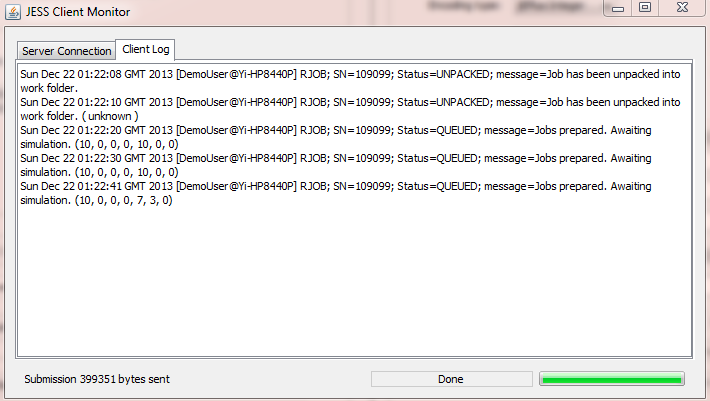
The remote simulation option uses the integrated JESS Client to send simulation jobs to a remote JESS server. If the JESS server is hosted on a powerful computer, such as the DMU cluster, you can get simulation results back much faster than running them on the local computer. For more details of how to use the JESS Client, and how to obtain an account on the DMU cluster, please see The jEPlus Simulation Server (JESS).
Screenshots below shows the options box and the simulation monitor for remote simulation.

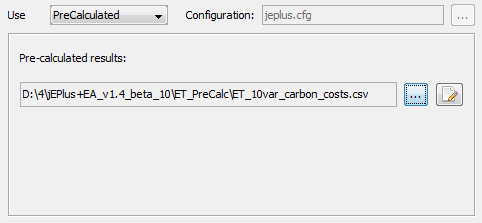
Use pre-calculated results
For doing experiments with the optimisation algorithms, it is often more efficient to read existing simulation results from a file, then running live simulations. The pre-calculated option is designed for this purpose. You can first run the full parametrics with you optimisation project, and then convert the result table into a format from which jEPlus+EA can look up values for each solution.
Below is an example pre-calculated result table file:
Id, Job_Id, Date/Time, Total CO2, Total cost 0, ET-0_0_0_0_0_0_0_0_0_0_0, simdays=365, 2234.812815, 1121.46975 1, ET-0_0_0_0_0_0_0_0_0_0_1, simdays=365, 2101.837728, 1713.46975 2, ET-0_0_0_0_0_0_0_0_0_0_2, simdays=365, 2058.685624, 2305.46975 3, ET-0_0_0_0_0_0_0_0_0_1_0, simdays=365, 2188.767806, 1241.026434 4, ET-0_0_0_0_0_0_0_0_0_1_1, simdays=365, 2060.231246, 1833.026434 ...
This file is in CSV format. The first and the third columns ('Id' and 'Date/Time' in the example) must be present, but are not read by jEPlus+EA. Simulation result data start from the fourth column. The first row of data (column headings) is ignored.
The main difference between this file to a jEPlus result table ('SimResutls.csv') is in the 2nd column, the 'Job_Id'. jEPlus+EA has its own naming convention for solutions in a project. As a result, manual conversion from the jEPlus job IDs to the jEPlus+EA job IDs is necessary.
The screenshot on the right is the PreCalculated option box.
EA settings explained
One of the distinctive features of jEPlus+EA is that a user can perform optimisation with a thorough understanding of the algorithms. Through our research, we have selected and customized the most robust and versatile optimisation algorithm to integrate into the program. For most problems, the default settings will work efficiently. There are nevertheless options you can adjust to suit your own task.

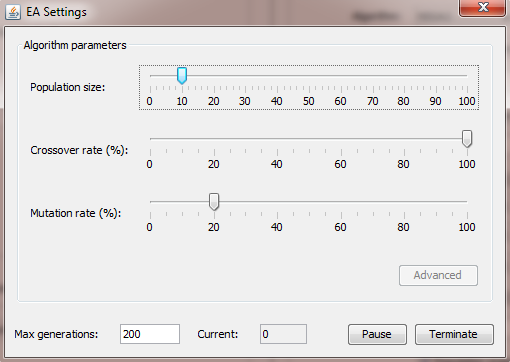
NSGA2 is the base algorithm used in jEPlus+EA. We have customized it to use integer encoding, hybrid crossover and mutation operators, and Pareto archiving methods. The efficacy of this algorithm is shown in our publications (see References). It is quite easy to find information on the concept of Evolutionary Algorithms. Here is a quick recap of the terminology used in jEPlus+EA GUI.
- Population size - the number of solutions to be evaluated in each iteration. More design variables requires larger population size in general. The choice is also influenced by the number of processor cores you have for running these simulations.
- Max generations - the number of iterations you want the optimisation to run. You can simply put a large enough number here, and terminate the process manually if enough solutions have been found.
- Crossover rate - how often the new solutions are created by merging features of existing solutions. A high value (towards 100%, or 1.0) is desirable.
- Mutation rate - how often random changes happen to the new solutions. A lower value is preferred; otherwise the algorithm may behave like a random trial and error.
- Tournament selection size - new solutions in EA are created from selected existing solutions. The selection process is stochastic, but influenced by the 'fitness' of the existing solutions. Tournament selection pick two (or more) solutions randomly from the existing population, and keep the better (best) one based on its fitness value. The larger the tournament size is, the harder the algorithm pushing towards the desired objectives. A tournament size of 2 is normally a good balance.
Output and log files
jEPlus+EA generates a number of log and data files during use. They are summarized below.
Error logs
The default log for program messages and exceptions is stored in “client.err”. This file can be renamed by editing the “log4j.cfg” configure file.

Workspace and autosave
During optimisation, jEPlus+EA saves the workspace automatically after each generation (iteration), to “autosave.obj” in the folder of the jEPlus+EA program. The workspace file stores most of the state of the program, including optimisation progress and charts. You can also save the workspace manually, and restore it by loading the file, to continue from the stored point.
Population snapshot
You can instruct jEPlus+EA to save a snapshot of the current solution population at regular intervals. The population snapshot file is a text file such as the one below. You can edit and use these files for “seeding” the optimisation.
# [Pop-10] 22 solutions; Best Solution: obj= -1.0 inf= -1.0; 0: ( 0 1 0 0 1 1 0 0 1 1 1 ); Evaluation: Objs = 1942.0551 2084.5813, , Rank = 1, Crowding = Infinity, Fitness = 0.0; Job_ID: ET-0_1_0_0_1_1_0_0_1_1_1 1: ( 0 0 0 0 0 0 0 0 0 0 0 ); Evaluation: Objs = 2234.81282 1121.46975, , Rank = 1, Crowding = Infinity, Fitness = 1.0; Job_ID: ET-0_0_0_0_0_0_0_0_0_0_0 2: ( 0 0 0 0 0 0 0 0 0 1 0 ); Evaluation: Objs = 2188.76781 1241.02643, , Rank = 1, Crowding = 0.42611974574498407, Fitness = 2.0; Job_ID: ET-0_0_0_0_0_0_0_0_0_1_0 3: ( 0 1 0 0 1 1 2 0 0 0 0 ); Evaluation: Objs = 2109.3017 1254.34099, , Rank = 1, Crowding = 0.4240160050260542, Fitness = 3.0; Job_ID: ET-0_1_0_0_1_1_2_0_0_0_0 4: ( 0 1 0 0 2 0 0 0 1 2 0 ); Evaluation: Objs = 2062.78102 1712.65719, , Rank = 1, Crowding = 0.4026611706720636, Fitness = 4.0; Job_ID: ET-0_1_0_0_2_0_0_0_1_2_0 ...
Other log files
There are a few other log files for debugging and analyzing algorithms. They are less useful for users.