meta data for this page
Chapter 5 Result Extraction
5.1 The RVX file format
Although it has been possible to extract SQLite output by extending the standard RVI file since version 1.4, the additional sections in the RVI files may be erased by EnergyPlus' version updater program. In jEPlus version 1.5, a new file format is introduced to provide a more robust and flexible solution.
Below is an example RVX (stands for RVI-extended) file. It is in fact a data structure represented in JSON format. It is not difficult to guess what the result extraction items do from the contents of this file. We will nevertheless explain further in the following sections.
{
"notes" : "Some notes about this RVX",
"rvis" : [
{
"fileName" : "5ZoneCostEst.rvi",
"tableName" : "SimResults"
}
],
"sqls" : [
{
"tableName" : "ChillerCap",
"columnHeaders" : "Chiller Nominal Capacity [W]",
"sqlcommand" : "select Value from ComponentSizes WHERE (CompType='Chiller:Electric' AND CompName='CHILLER PLANT CHILLER' AND Description='Nominal Capacity')"
},
{
"tableName" : "ConsCost",
"columnHeaders" : "Construction Cost [$/m2]",
"sqlcommand" : "select Value from TabularDataWithStrings WHERE (ReportName='Construction Cost Estimate Summary' AND ReportForString='Entire Facility' AND TableName='Construction Cost Estimate Summary' AND RowName='Cost Per Conditioned Building Area (~~$~~/m2)' AND ColumnName='Current Bldg. Model' AND Units='' AND RowId=10)"
}
],
"scripts" : [
{
"fileName" : "readRunTimes_jy.py",
"pythonVersion" : "jython",
"onEachJob" : false,
"arguments" : "",
"tableName" : "CpuTime"
}
],
"userVars" : [
{
"identifier" : "v0",
"formula" : "c0",
"caption" : "Variable 0 []",
"report" : false
},
{
"identifier" : "v1",
"formula" : "c1",
"caption" : "Variable 1 []",
"report" : true
},
{
"identifier" : "v2",
"formula" : "c2",
"caption" : "Variable 2 []",
"report" : false
}
],
"constraints" : [
{
"identifier" : "s1",
"formula" : "v1/1000",
"caption" : "Chiller Capacity [kW]",
"scaling" : true,
"lb" : 0,
"ub" : 200,
"min" : 0,
"max" : 300,
"weight" : 1.0
}
],
"objectives" : [
{
"identifier" : "t1",
"formula" : "v0/1000/3600",
"caption" : "Electricity [kWh]",
"scaling" : true,
"min" : 0,
"max" : 100000,
"weight" : 1.0
},
{
"identifier" : "t2",
"formula" : "v2",
"caption" : "Construction Cost [$/m2]",
"scaling" : false,
"min" : 0,
"max" : 1000,
"weight" : 1.0
}
]
}
5.2 Structure of RVX
As you can see from the example above, a RVX contains 7 components, which are notes, rvis, sqls, scripts, userVars, constraints, and objectives. The notes holds only one text string that serves as comments of the RVX file, as no other comment line is allowed in JSON format. The rvis, sqls and scripts components define result extractors, which we will explain in sections 5.3 - 5.5. The userVars, constraints and objectives components are user-defined report variables, useful for doing calculations from the simulation results.
The JSON data format is fairly straightforward. A component (or object) is wrapped in a pair of { }. A list of components is wrapped in [ ]. Members of a list or a component are separated with ,. Except for notes, all other components of the RVX are in fact lists. JSON is designed for programmatic data exchange rather than user input; therefore the syntax rules are very strict and may cause trouble to new users. Here are a few things you need to take care when editing this file:
- The reference of each member, i.e. the text on the left side of a
:, must not be changed “ ”,[ ],{ }pairs must be matched- No excess or missing
,
It may be easier to use a dedicated JSON editor to check over your RVX file.
5.3 Use ReadVarsEso and the RVI/MVI files
ReadVarsESO is a very useful tool in EnergyPlus and has been used in jEPlus since its first release. ReadVarsESO extract data of user selected variables from the standard EnergyPlus output files (eplusout.eso and eplusout.mtr) and reformat it as a CSV file. More details of how ReadVarsESO works can be found in EnergyPlus' documentation. To use ReadVarsESO, you need to specify a RVI or MVI file, which contains the name of the EnergyPlus output file (either eplusout.eso or eplusout.mtr), the name of the output CSV file (must be eplusout.csv), a list of output variables to extract, and a 0 in the last row to mark the end of the file. List below shows an example of RVI.
eplusout.mtr eplusout.csv Electricity:Facility 0
The available output variable names of your model are reported in eplusout.rdd and eplusout.mdd (or your_model_name.mdd/rdd, if you simulated the model with EP-Launch) files. Below is (part of) an example eplusout.mdd file, in which you can see where the variable names are specified. Please note the variables must be specified for output at the desired frequency in the IDF model, too.
Program Version,EnergyPlus-32 7.0.0.036, 06/06/2013 20:46,IDD_Version 7.0.0.036 Var Type (reported time step),Var Report Type,Variable Name [Units] Zone,Meter,Electricity:Facility [J] Zone,Meter,Electricity:Building [J] Zone,Meter,Electricity:Zone:SPACE1-1 [J] Zone,Meter,InteriorLights:Electricity [J] Zone,Meter,InteriorLights:Electricity:Zone:SPACE1-1 [J] Zone,Meter,GeneralLights:InteriorLights:Electricity [J] ...
Prior to version 1.5, jEPlus can only use one RVI file to extract results. This has changed with the introduction of the RVX file. In a RVX, you can specify as many RVI files to use as you like in the rvis component. Below is an example showing the syntax. In addition to the RVI file name, you should specify a table name. Each RVI extracts results to a eplusout.csv file, which will then be renamed to [tableName].csv by jEPlus to avoid conflicts between different RVIs.
{
...,
"rvis" : [
{
"fileName" : "5ZoneCostEst.rvi",
"tableName" : "SimResults"
},
{
"fileName" : "another.rvi",
"tableName" : "MoreResults"
}
],
...
}
5.4 Extract SQLite output
Certain simulation results from EnergyPlus simulation is only available from the tabular outputs in eplusout.sql. Since version 1.4, jEPlus can extract such results by using SQL and the built SQLite driver. For more details on how to prepare SQLite instructions, please refer to the video guide.
Below is an example of a RVI file extension used in version 1.4. The standard RVI instructions ends at the line containing only 0. Three additional blocks are appended. The first block starts with !-sqlite and ends with !-end sqlite, containing instructions on data extraction from the SQLite tables. This syntax is still accepted in version 1.5. However, if the RVI file is passed through the EnergyPlus version updater, the additional blocks will be lost. A better solution is the new RVX file.
eplusout.mtr eplusout.csv Electricity:Facility 0 !-sqlite ! Output file name; Column headers; SQL command ChillerCap; Chiller Nominal Capacity [W]; select Value from ComponentSizes WHERE (CompType='Chiller:Electric' AND CompName='CHILLER PLANT CHILLER' AND Description='Nominal Capacity') ConsCost; Construction Cost [$/m2]; select Value from TabularDataWithStrings WHERE (ReportName='Construction Cost Estimate Summary' AND ReportForString='Entire Facility' AND TableName='Construction Cost Estimate Summary' AND RowName='Cost Per Conditioned Building Area (~~$~~/m2)' AND ColumnName='Current Bldg. Model' AND Units='' AND RowId=10) !-end sqlite !
The list below is the sqls component of the RVX example. Each sql item has a tableName, a set of columnHeaders, and a sqlcommand. jEPlus will execute the sqlcommand on each job's eplusout.sql output file, and store result(s) in the [tableName].csv, with the given columnHeaders. You can have as many sql items in this section as you like.
{
...
"sqls" : [
{
"tableName" : "ChillerCap",
"columnHeaders" : "Chiller Nominal Capacity [W]",
"sqlcommand" : "select Value from ComponentSizes WHERE (CompType='Chiller:Electric' AND CompName='CHILLER PLANT CHILLER' AND Description='Nominal Capacity')"
},
{
"tableName" : "ConsCost",
"columnHeaders" : "Construction Cost [$/m2]",
"sqlcommand" : "select Value from TabularDataWithStrings WHERE (ReportName='Construction Cost Estimate Summary' AND ReportForString='Entire Facility' AND TableName='Construction Cost Estimate Summary' AND RowName='Cost Per Conditioned Building Area (~~$~~/m2)' AND ColumnName='Current Bldg. Model' AND Units='' AND RowId=10)"
}
],
...
}
5.5 Use Python Scripts
Probably the most significant feature introduced in version 1.5 is the ability to run Python scripts in the data collection process. This gives user virtually infinite possibilities for post-processing simulation results. Here is the scripts components in the RVX for specifying Python scripts for extracting data.
{
...
"scripts" : [
{
"fileName" : "readRunTimes_jy.py",
"pythonVersion" : "jython",
"onEachJob" : false,
"arguments" : "",
"tableName" : "CpuTime"
}
],
...
}
Description of the fields
The fields in each script item require a bit of explaination:
fileName– The file name of the Python script. If full path is not provided, it is relative to the location of this RVX file.tableName– The file name for the output table. Value of this field will be passed to the Python script as the third argument. The script is then responsible for producing a csv table similar to the RVI result.pythonVersion– Unfortunately the Python language differs between version 2 and 3. There are also restrictions depending on the interpreter used. In this field you can selectjython,python2orpython3.onEachJob–trueorfalse. If true, the script will be executed in each job folder, otherwise in the project's output folder where the individual job folders are located. If notonEachJob, a list of jobs in the project will be passed to the script as the second argument.arguments– You can provide additional arguments to be passed to the script. All additional arguments should be specified in one text string, separated by,.
Arguments passed to the script
The number of arguments jEPlus passes to the script varies depending on a few factors. If the script is run in the project's output folder (i.e. the onEachJob field is set to false), jEPlus will pass three arguments plus the additional ones defined by user. The arguments can be read within the script using sys.argv[]. Note that sys.argv[0] returns the name of the script.
- sys.argv[1] – the full path of the output folder of the project where the individual job folders are located
- sys.argv[2] – the list of IDs of the jobs have been executed in the project
- sys.argv[3] – user-defined output table name + .csv
- sys.argv[4..] – Other arguments specified in the RVX file
Alternatively, if the script is run in each individual job folder, the arguments passed are as below:
- sys.argv[1] – the full path of the job folder
- sys.argv[2] – user-defined output table name + .csv
- sys.argv[3..] – Other arguments specified in the RVX file
Output table format
The Python scripts are responsible to produce suitable output tables that jEPlus can read and include into its result collection process. Depending on where the script is run, the output table formats are different.
If a script is run in the individual jobs folders, the output table should mimic the format of a typical eplusout.csv file generated by ReadVarsESO. Basically, the first column is date and time; the rest are data. Here is an example:
Date/Time,InteriorLights:Electricity [J](Hourly),InteriorEquipment:Electricity [J](Hourly),Heating:DistrictHeating [J](Hourly) 01/01 01:00:00,0.0,2276640.,13278931.1044949 01/01 02:00:00,0.0,2276640.,32229908.1477126 01/01 03:00:00,0.0,2276640.,17895859.9832406 01/01 04:00:00,0.0,2276640.,38784519.4821989 ...
A script running in the project's output folder should produce a table similar to SimResults.csv. The table should have three columns before the start of data. These three columns are the serial IDs, the job IDs, and a reserved column that can be anything or left empty. Below is an example. Please note the header row must start with #
#, Job_ID, Date/Time, Electricity:Facility [J](RunPeriod) 0, LHS-000000, simdays=62, 233879205202.003 1, LHS-000001, simdays=62, 236359323510.063 2, LHS-000002, simdays=62, 248514348464.105 3, LHS-000003, simdays=62, 232542002313.733 4, LHS-000004, simdays=62, 248299129214.135 5, LHS-000005, simdays=62, 250977825693.01 6, LHS-000006, simdays=62, 239737768305.779 ...
Notes on Jython
Jython is Python language implemented in Java and runs on a Java virtual machine. Its development lags behind the C Pyhton, and support on Python 2.5 at present. Jython is included in jEPlus for people who do not need to full power of Python nor have C Python installed on their computers. Despite its limitations (see below), Jython provides a convenient way of having simple scripts in a jEPlus project.
- Language level support: Python 2.5
- Only the core libraries, no extensions or plugins available
- Script will be executed in the jEPlus folder, instead of the project output folder or the individual job folder
- There are some odd issues, such as the csv package must be referenced as
_csv
The example script
The following script is included in the example_2-rvx_E+v8.1/ folder. It reads the RunTimes.csv table and calculates the CPU time in seconds, before writing the results to an output table. This script is just for demonstration purpose and has probably little practical use. However, you can see how scripts work with jEPlus.
# Example python script: This script reads from RunTimes.csv, calculates CPU time used in seconds,
# and then write to different table specified by the user.
# Arguments:
# sys.argv[1] - output folder of the project where the RunTimes.csv is located
# sys.argv[2] - the list of jobs have been executed in the project
# sys.argv[3] - user-defined output table name + .csv
# sys.argv[4..] - Other arguments specified in the RVX file
import sys
import _csv
import math
ifile = open(sys.argv[1] + "RunTimes.csv", "rt")
reader = _csv.reader(ifile)
ofile = open(sys.argv[1] + sys.argv[3], "wb")
writer = _csv.writer(ofile)
rownum = 0
timelist = []
for row in reader:
# Save header row.
if rownum == 0:
header = row[0:3]
header.append("CpuTime")
writer.writerow(header)
else:
time = [float(t) for t in row[5:]]
seconds = time[0]*3600+time[1]*60+time[2]
timelist.append(seconds)
temprow = row[0:3]
temprow.append(seconds)
writer.writerow(temprow)
rownum += 1
ifile.close()
ofile.close()
n = len(timelist)
mean = sum(timelist) / n
sd = math.sqrt(sum((x-mean)**2 for x in timelist) / n)
print '%(n)d jobs done, mean simulation time = %(mean).2fs, stdev = %(sd).2fs' % {'n':n, 'mean':mean, 'sd':sd}
The console errors and outputs (including the print… output) are logged in PyConsole.log file in the project's output folder. If a script is run in the individual job folders, the console logs are stored in the console.log files in each job folder.
5.6 User-defined Report Variables
Finally, the RVX file allows user to define a number of derivative variables from the collected simulation results, and define scaled (or normalized) metrics that can be used as constraints and objectives in optimization processes. Below are these components in the example RVX.
{
...,
"userVars" : [
{
"identifier" : "v0",
"formula" : "c0",
"caption" : "Variable 0 []",
"report" : false
},
{
"identifier" : "v1",
"formula" : "c1",
"caption" : "Variable 1 []",
"report" : true
},
{
"identifier" : "v2",
"formula" : "c2",
"caption" : "Variable 2 []",
"report" : false
}
],
"constraints" : [
{
"identifier" : "s1",
"formula" : "v1/1000",
"caption" : "Chiller Capacity [kW]",
"scaling" : true,
"lb" : 0,
"ub" : 200,
"min" : 0,
"max" : 300,
"weight" : 1.0
}
],
"objectives" : [
{
"identifier" : "t1",
"formula" : "v0/1000/3600",
"caption" : "Electricity [kWh]",
"scaling" : true,
"min" : 0,
"max" : 100000,
"weight" : 1.0
},
{
"identifier" : "t2",
"formula" : "v2",
"caption" : "Construction Cost [$/m2]",
"scaling" : false,
"min" : 0,
"max" : 1000,
"weight" : 1.0
}
]
}
jEPlus will compute all these variables and metrics after collecting simulation results, and put the values in the AllDerivedResults.csv file. Here are some notes about the variables.
- The identifier of each variable or metric should be unique
- The order of definitions of the variables is significant, as jEPlus computes the variables following the definition sequence.
- Parameters (e.g P1, P2…) are NOT accessible in post-processing
- You can choose to include a variable in the output table or not. The metrics are always included.
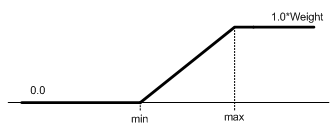
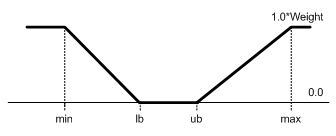
- A metric is a variable with a special scaling function
- If scaling is enabled, a constraint will be normalized as illustrated in Figure 5.1.
- An objective's scaling is illustrated in Figure 5.2
- For help with the formulas, please refer to the Java Expression Parser